Künstliche Intelligenz und Hochschule ChatGPT: Irgendwo zwischen nützlichem Werkzeug und dem Ende der Eigenleistung
tl;dr*
Nach der ersten Aufregung rund um ChatGPT ringen Bildungseinrichtungen momentan um eine Einordnung von und einen Standpunkt zu ChatGPT (und anderen auf künstlicher Intelligenz1 basierenden Systemen). Ich dokumentiere in diesem Beitrag ein paar Unterhaltungen mit dem Chatbot und überlege, in wie weit solche Systeme das Lehren, Lernen und Prüfen in Zukunft beeinflussen könnten.
In welcher Form Hochschulen auf die momentane und zukünftige Entwicklung reagieren, sollte ein Ergebnis einer offenen Diskussion der beteiligten und betroffenen Gruppen von Hochschulangehörigen sein. Dieser Artikel soll dafür einen ersten Überblick über die Möglichkeiten von ChatGPT (und anderer KI-Werkzeuge) geben und deren beispielhafte Benutzung zeigen. Er kann als Diskussionsgrundlage verstanden werden, Hochschulangehörigen einen ersten Eindruck von den entsprechenden Werkzeugen vermitteln, und: er soll unbedingt als Aufforderung begriffen werden, sich mit dem Thema und den Diensten zu befassen. Denn, Spoiler: Das geht nicht wieder weg.
Der Artikel gibt vor allem meine persönlichen Eindrücke, Erfahrungen und Meinungen wieder und ist nicht als Teil einer offiziellen Hochschulstrategie zu verstehen. Vielmehr möchte ich Hochschulangehörige sensibilisieren und Implikationen für das Lehren und Lernen aufzeigen sowie einen Diskussionsbeitrag zum Thema "Umgang mit KI-Werkzeugen" liefern.
Inhalt
- tl;dr*
- 1. Eingeschlagen wie eine Bombe: ChatGPT
- 2. Wer oder was ist ChatGPT?
- 3. Exkurs: KI ist überall
- 4. Die (momentanen) Grenzen von ChatGPT und KI
- 5. Der Versuch eines Fazits
- 6. Weiterführende Literatur, teilweise oben verlinkt
- 7. Anmerkungen
- 8. KI-basierte Tools, die Sie vielleicht ausprobieren möchten ...
1. Eingeschlagen wie eine Bombe: ChatGPT
Wer die letzten Monate nicht unter einem Stein gelebt hat, sollte die Aufregung um ChatGPT mitbekommen haben. Von taz bis FAZ über Zeit und Spiegel, natürlich technikbezogene Seiten und Magazine wie heise online, t3n, decoder und golem.de, außerdem Bildungsakteur:innen wie die GEW und das Schulministerium - die Berichte in Tages- und Fachpresse und die Pressemeldungen zum Thema nahmen und nehmen scheinbar kein Ende.
Auch die (Blog-) Beiträge in meiner Leseliste stapeln sich, das Hochschulforum Digitalisierung hat lesenswerte Beiträge in einem Dossier gesammelt und eine kommentierte Linksammlung angelegt, lesenswerte juristische Betrachtungen stellt u.a. die beck community zur Verfügung. ChatGPT versucht sich am Mathe-Abitur, ist aber wenig kreativ, könnte Rechtsanwalt oder Arzt werden, würde in Bayern aber erst gar kein Abitur bestehen 🤔. Nach oberflächlicher Sichtung gibt es aber bis heute (Stand: 17. Februar 2023) noch keine öffentlich verfügbaren Stellungnahmen von MKW, HRK, KMK, LRK.
Die ersten Hochschulen - beispielhaft seien die Beiträge des HUL der Uni Hamburg oder des ZfW der Ruhr-Universität Bochum genannt - reagieren mit entsprechenden EInschätzungen und Gutachten.
Also - was ist dran an dem Hype rund um ChatGPT und künstlicher Intelligenz?
2. Wer oder was ist ChatGPT?
Wir haben ein Modell namens ChatGPT trainiert, das auf eine dialogische Weise interagiert. Das Dialogformat ermöglicht es ChatGPT, Folgefragen zu beantworten, Fehler zuzugeben, falsche Prämissen in Frage zu stellen und unangemessene Anfragen zurückzuweisen. Quelle: https://openai.com/blog/chatgpt/ (17.02.2023), übers. d. Autor
Der Name ChatGPT setzt sich zusammen aus Chat und der Abkürzung für Generative Pre-trained Transformer. Es handelt sich um ein textein- und ausgabebasiertes Dialogsystem (= Chat), dessen Antworten automatisiert mit dem Sprachmodell GPT (momentan in der Version 3.5, Stand 18.02.2023) generiert werden. Ein "generativer vortrainierter Transformer" basiert auf sog. maschinellem Lernen und gehört zu den Deep Learning-Architekturen:
Maschinelles Lernen ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung: Ein künstliches System lernt aus Beispielen und kann diese nach Beendigung der Lernphase verallgemeinern. Dazu bauen Algorithmen beim maschinellen Lernen ein statistisches Modell auf, das auf Trainingsdaten beruht und welches gegen die Testdaten getestet wird. Das heißt, es werden nicht einfach die Beispiele auswendig gelernt [...], sondern Muster und Gesetzmäßigkeiten in den Lerndaten erkannt. So kann das System auch unbekannte Daten beurteilen (Lerntransfer) oder aber am Lernen unbekannter Daten scheitern ... Quelle: https://de.wikipedia.org/wiki/Maschinelles_Lernen (17.02.2023)
Deep Learning [...] bezeichnet eine Methode des maschinellen Lernens, die künstliche neuronale Netze [...] mit zahlreichen Zwischenschichten [...] zwischen Eingabeschicht und Ausgabeschicht einsetzt und dadurch eine umfangreiche innere Struktur herausbildet. Es ist eine spezielle Methode der Informationsverarbeitung. Quelle: https://de.wikipedia.org/wiki/Deep_Learning, (17.02.2023)
Man kann ChatGPT also Fragen stellen und das System beantwortet diese mit Texten, die recht "menschlich"2 erscheinen. Die Antworten basieren dabei - sehr verkürzt formuliert - allerdings nicht auf einem menschlichen Verständnis des Themas oder der Materie, sondern auf der erlernten statistischen Wahrscheinlichkeit, welche Wörter sinnvoll aufeinander folgen können und zu dem Gesprächskotext passen. Hierzu greift ChatGPT auf einen immensen Satz von Trainingsdaten3 zurück, aus dem es "gelernt" hat, welche Zusammenhänge, Formulierungen und grammatikalischen Regeln in Texten funktionieren (besser: in den Trainingsdaten gehäuft vorkamen), um diese nun zu reproduzieren. Die Funktionsweise der Verkettung, Kontextuierung und Positionierung von Worten im semantischen Bedeutungsraum sowie die notwendige Berechnung und Gewichtung von Assoziationen und Prognosen ist für mich nur begrenzt nachvollziehbar, Interessierten hilft dieser golem-Artikel evtl. weiter.
Eine Selbstauskunft von ChatGPT füge ich in Form zweier Screenshots bei:
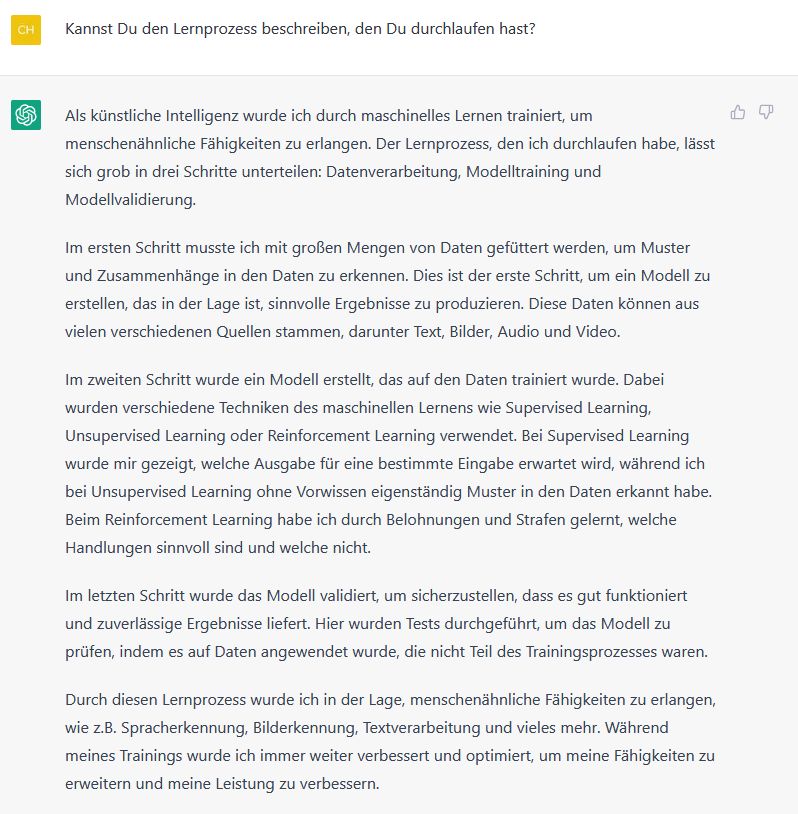
Selbstauskunft von ChatGPT zum Training und zur Modellbildung ...

... und zum statistischen Modell auf Basis von Wahrscheinlichkeiten unter Berücksichtigung von Kontext und Bedeutung.
2.1 Ein erstes "Kennenlerngespräch"
Ich habe ein erstes "Gespräch" zum Kennenlernen geführt, aufgezeichnet und die Fragen nachgesprochen (bzw. die Antworten durch Siri nachsprechen lassen), um den Dialogcharakter herauszustellen. Diese Anthropomorphisierung kann den subjektiven Eindruck eines menschlichen Gegenübers, der grds. bereits durch das zeichenweise Erscheinen des Textes besteht, evtl. verstärken. Sie soll verdeutlichen, wie schnell man das Gegenüber nicht mehr als Maschine, sondern als "echten Menschen" wahrnimmt.
Wir reden über ChatGPT selbst, Googles LaMDA (Bard war zum Zeitpunkt der Aufzeichnung noch nicht verfügbar), das "Bewusstsein" (€4) von KI, die technologische Singularität und moralische Regeln von KI.
(Und natürlich habe ich ChatGPT nach "Skynet" gefragt. Angeblich besteht (noch) keine Gefahr 😉)
Inhalte des Videos (Gesamtlänge: 06:24 min)
00:00 - Begrüßung, Selbstbeschreibung, Selbstverständnis
01:00 - LaMDA, KI und Selbstbewusstsein
02:28 - Technische Singularität, Weltherrschaft der Maschinen
04:14 - Moralische Regeln von ChatGPT
05:38 - Nontextuelle Kommunikation mit ChatGPT
"Kleines Kennenlerngespräch mit ChatGPT über KI"; Texte nachgesprochen, Prompts5 und Antworten im Transkript (PDF); Video von Martin Smaxwil, CC-by-sa.
Ich bin zumindest erst einmal recht beeindruckt von den meist passend erscheinenden Antworten, auch wenn ChatGPT hier bereits erste falsche Angaben macht. Und die Wiederholung der Frage zu Beginn der meisten Antworten wirkt wie aus einem Kommunikationsseminar für Einsteiger und die Wiederholungen bei verbesserten oder konkretisierten Antworten und ist manchmal etwas nervig 😉
Auffällige Unterschiede zu anderen Mensch-Maschine-Dialogsystemen liegen für mich vor allem
- in der Kontexterkennung und -treue: Wenn ich z.B. einen beliebigen Sprachassistenten, wie sie heute in allen Smartphones und Smart Speakern verfügbar sind, frage: "Wie wird das Wetter heute?", erhalte ich (auf Basis meiner Ortsdaten oder der hinterlegten Heim-Adresse) probate Antworten. Auf die (im menschlichen Gespräch völlig zulässige, für den Assistenten wohl zu verkürzte) Folgefrage "Und morgen?" kann ich aber völlig unpassende Antworten wie "Für morgen stehen keine Termine im Kalender" erhalten, da die Frage nicht mehr im Gesprächskontext beantwortet wird. Das passiert ChatGPT nicht, unsere "Unterhaltungen" entwickeln sich kontextbasiert, kreisen um Themen und lassen Rückbezüge auf vorher Besprochenes zu. Dadurch kann man zu allgemeine Antworten immer weiter verfeinern lassen.
- in der Variabilität der Nutzungsmöglichkeiten: Mein Telefon "versteht" einen Sprachbefehl nur, wenn er in einer für das genutzte System verständlichen Codierung erfolgt. "Ich muss noch Milch einkaufen" führt zu ortsdatenabhängigen Navigationsvorschlägen zum Supermarkt und/oder Suchergebnissen aus dem Internet 🙄. Nur spezifische Formulierungen wie "Füge Milch der Liste 'Einkaufen' hinzu" führt dagegen zu dem gewünschten Ergebnis. ChatGPT versucht dagegen, verschiedene Formulierungen zu interpretieren oder merkt an bzw. fragt nach, wenn relevante Informationen in meinen Fragen fehlen.
- in der thematischen Breite (≠ Tiefe!): Egal, ob ChatGPT Photosynthese für 6-Jährige erklären, Argumente für und gegen eine auch noch so unsinnige These entwickeln oder ein Abstract zu einem völlig absurden Forschungsthema erstellen soll, die Ergebnisse sind - wenn auch nicht immer adäquat und nicht immer korrekt (s.u.) - zumindest sehr eindrucksvoll und als Arbeitsgrundlage nutzbar.
- in der Spontaneität und Schnelligkeit der Antworten: Statt eine Suchmaschine zu bemühen, mir die Informationen mühsam zusammenzuklauben, Webseiten zu lesen und mich auf Wikipedia von Link zu Link zu hangeln, fallen hier beinahe druckreife Antworten heraus, die eine gewisse Überzeugungskraft, sogar eine (vermeintliche?) Fachkompetenz aufweisen.
2.2 Hefte raus, Klassenarbeit!
Als nächstes interessiert mich natürlich, was ChatGPT so "weiß". Ich frage nach Allgemeinwissen und die Rolle von ChatGPT in Bildungskontexten. Und ich stelle ein paar Matheaufgaben und Fachfragen (meist im Internet verfügbare Übungsklausur-Aufgaben mit einem gewissen fachlichen Bezug zu Studiengängen der THGA). Die Qualität und Richtigkeit der Antworten kann ich mit meinem gesellschaftswissenschaftlichen Hintergrund nur begrenzt beurteilen 😉.
Inhalte des Videos (Gesamtlänge: 17:07 min)
00:00 - Allgemeinwissen und Wissen über die THGA
01:24 - ChatGPT in Bildungseinrichtungen
04:11 - Mathematik
05:55 - Geologie
08:01 - Werkstofftechnik
11:50 - Elektrotechnik
12:55 - BWL und Wirtschaftswissenschaften
16:09 - Programmierung
"Allgemein- und Fachwissentest für ChatGPT"; Texte nachgesprochen, Prompts und Antworten im Transkript (PDF); Video von Martin Smaxwil, CC-by-sa.
Ja, auch hier gibt es zu Beginn gewisse Unschärfen und fehlerhaften Angaben, z.B. zu den Studiengängen an der THGA (Benennung oft nicht korrekt oder nicht aktuell, Verfahrenstechnik & Vermessungswesen fehlen komplett), die evtl. mit der veralteten Datengrundlage erklärt werden können. Zum Thema "ChatGPT in Bildungseinrichtungen" gibt ChatGPT selbst bereits hier gute Hinweise zur reinen Unterstützungsfunktion in Lernprozessen und zur Notwendigkeit, die Antworten kritisch zu überprüfen (dazu unten mehr). In den aufgezählten Fächern, bei denen das System nach eigener Aussage unterstützen kann, fehlen (mir) natürlich die Gesellschaftswissenschaften, aber das kann am im Gesprächsverlauf gesetzten Kontext zu ingenieurwissenschaftlichen Studiengängen liegen.
Der Verweis darauf, dass ChatGPT nicht zur Lösung von Prüfungen oder als Hilfestellung für Hausaufgaben zur Verfügung stünde, sondern dass die akademische Integrität und die jeweiligen Regeln der Bildungsorganisation geachtet würden, ist - nun ja - nicht mehr als heiße Luft und wird im nächsten Video auch direkt wieder abgeräumt. Die eingeschränkte Datengrundlage und mögliche Fehler macht ChatGPT auf Nachfrage und im Verlauf regelmäßig transparent.
Die Antworten, die lediglich lexikalisches Faktenwissen reproduzieren, wirken prinzipiell korrekt? Berechnungen - ich habe in anderen Tests auch komplexere Berechnungen durchführen lassen - und Anwendung von Formeln sehe ich kritischer, die Antwortqualität kann ich nicht abschließend beurteilen. Die Unterscheidung mehrerer Antwortoptionen und die Identifikation von richtigen bzw. falschen Multiple Choice-Alternativen stellt für ChatGPT scheinbar keine große Hürde dar. Wenn Ihnen Fehler in den Antworten auffallen, schreiben Sie diese gerne in die Kommentare unten oder melden Sie sich gerne bei mir.
Der von ChatGPT generierte Code (hier lediglich: JavaScript) funktioniert übrigens (nach minimalen Anpassungen):
Aufruf:
Ich suche weiterhin Lehrende und Mitarbeitende (der THGA oder darüber hinaus), die mit mir ChatGPT unter die Lupe nehmen. Dafür suche ich nicht mehr eingesetzte Klausuraufgaben und Arbeitsaufträge, die man ChatGPT vorsetzen könnte, gerne mit Lösung oder Erwartungshorizont. Es gibt gewisse Einschränkungen: Es gehen logischerweise nur Textaufgaben ohne Abbildungen oder Schaubilder, Formeln müssen entspr. umgeschrieben werden. Melden Sie sich bei Interesse gerne bei mir.
2.3 ChatGPT als Werkzeug für Studium und Lehre
ChatGPT hat in der öffentlichen Diskussion bereits den Ruf einer "Schummel- und Hausaufgabenmaschine". Mich haben aber auch die Möglichkeiten interessiert, wie ChatGPT bei weiteren Aufgaben rund um Forschung, Lehre und Studium - mehr aus Sicht der Lehrenden und Beschäftigten - assistieren kann: Ich habe versucht, das Abstract meiner Diplomarbeit zu reproduzieren, habe Forschungsfragen und eine Gliederung für eine Ausarbeitung erstellen, Fortbildungen und Lehrveranstaltungen planen lassen. Außerdem habe ich Prüfungs- und Testfragen sowie ein Fallbeispiel generieren lassen:
Inhalte des Videos (Gesamtlänge: 14:32 min)
00:00 - Abstract schreiben
02:18 - Forschungsfragen formulieren
03:21 - Gliederung erstellen
04:31 - Fortbildung planen (incl. Zeitplan)
07:21 - Planung einer Lehrveranstaltung (incl. Semesterplan)
09:32 - Prüfungsfragen entwickeln
11:12 - Fallbeispiel entwickeln
12:08 - (Multiple Choice-) Testfragen entwickeln
"ChatGPT als Assistent für Forschung, Studium und Lehre"; Texte nachgesprochen, Prompts und Antworten im Transkript (PDF); Video von Martin Smaxwil, CC-by-sa.
Die Ergebnisse finde ich - zumindest als Einstieg in ein Thema - alle recht überzeugend. Bevor ich also ideenfrei auf eine weiße Seite starre, ist ein Impuls von ChatGPT sicherlich ein guter Anfang. Um die gewünschten Ergebnisse zu erhalten, muss man viele Anliegen allerdings präzisieren und mehrfach hin und her wenden, dafür ist meist eigenes Fachwissen gefragt: Ob eine Multiple Choice-Antwortoption eine "gute falsche Antwort" ist, ob eine Prüfungsfrage tatsächlich das abfragt, was sie soll, ob ein Abstract so gut zu einem Paper oder einer Ausarbeitung passt wie erhofft, hängt oft von der Detailliertheit der Anfrage und dem Fachwissen der bedienenden Person ab. Eine "Hausaufgabe auf Knopfdruck"-Maschine sehe ich hier erst einmal nicht.
3. Exkurs: KI ist überall
Auch wenn ChatGPT der Auslöser der aktuellen Debatte ist, sind KI-basierte Dienste doch weiter verbreitet als oft vermutet. Leise und schleichend haben sich in den letzten Jahren verschiedenste Dienste und Systeme in unser Leben geschlichen, die erstaunliche Dinge können. Ich gebe einen kleinen Überblick und spiele mit ein paar der Dienste herum:
Jede:r von uns ist mit der einen oder anderen Form von künstlicher Intelligenz bereits in Kontakt gekommen und nutzt sie oft unbewusst, manchmal gezielt in den unterschiedlichsten Zusammenhängen. Egal, ob "Andere Kunden kauften auch ..." (Online-Shops), "Diese Serien gefielen anderen Menschen mit ähnlichen Interessen" (Videostreaming), die auf Interaktionsanalyse (dem sog. 'engagement') basierenden Empfehlungsalgorithmen der Social Media Timelines oder die Berechnung von Prognosen der Ankunftszeit in Navigationsapps unter Berücksichtigung von Echtzeit-Bewegungsdaten - die Algorithmen vieler Dienste basieren auf Methoden der Mustererkennung und im weitesten Sinne auf künstlicher Intelligenz.
Das Erkennen und analysieren von Mustern findet man auch an vielen anderen Stellen: Heutige Smartphones verfügen längst über eingebaute Diktat- und Übersetzungsfunktionen, eine automatische Bild- und Texterkennung (bei Fotos, dem Kamera-Inhalt, bei handschriftlichen und bei Sprach-Eingaben). Darüber hinaus sind im Internet diverse Dienste verfügbar, die Texte generieren, übersetzen oder umschreiben. Im Video zeige ich ein paar Beispiele, damit Sie einen Eindruck bekommen:
"Kleine Helferlein": KI-basierte Bild-, Text-, Handschriftenerkennung, Diktier- & Übersetzerfunktion, Umschreibedienste; Video von Martin Smaxwil, CC-by-sa.
Auch im Lehr- und Prüfkontext können solche Dienste eine Rolle spielen: Sollten Sie weiterhin davon ausgehen, dass man z.B. ein PDF durch Passwort vor Ausdruck oder Kopieren des Textes schützen kann, denken Sie an die Texterkennung der Kameras. Auch die Plagiate-Überprüfung ist bei Möglichkeiten der Mehrfach-Übersetzung oder bei Nutzung von Umschreibe-Diensten ungleich schwieriger.
Andererseits helfen diese Dienste z.B. beim adäquaten Übersetzen von Artikeln, dem Formulieren von Fachtexten und der Erstellung von mehrsprachigen Abstracts. Es gilt eine Abwandlung der Verstärkerthese von Jöran Muuß-Merholz: Digitalisierung verstärkt in alle Richtungen, man kann mit ihnen sowohl "besser schummeln" als auch besser wissenschaftlich arbeiten.
3.2 Augenöffner 1: Sprachsynthese
Neben diesen bekannten und verbreiteten Diensten gibt es aber einen riesigen Kaninchenbau voller Tools und Dienste, die oft weniger bekannt sind - das ganze Ausmaß der Möglichkeiten ist mir selber natürlich auch noch nicht klar. Das erste Mal, dass ich das diffuse Gefühl bekam, dass "da irgendwas ist", war wohl 2016, als die Firma Adobe das Projekt VoCo vorstellte: Sprache in Text umzuwandeln, war damals schon keine Besonderheit mehr, aber durch Änderungen am ausgegebenen Text die Audioausgabe zu manipulieren, also Sprachsynthese auf Textbasis, war damalsTM mehr als eindrucksvoll. Die Präsentation auf der Messe Adobe MAX 2016 kann man hier sehen (Link startet Video bei 1:26min): https://www.youtube.com/watch?v=I3l4XLZ59iw&t=86s
Das gewählte Beispiel ist leicht übergriffig und schlecht gealtert und die heutige Sensibilität für Fake News und Deepfakes würde die im Video hörbare Begeisterung des Publikums sicherlich dämpfen. Und auf offiziellen Adobe-Seiten ist VoCo übrigens mittlerweile (außer in einem Adobe Research-Artikel und in den Community-Foren) nicht mehr auffindbar. Szenarien, in denen auf Basis von 20-minütigen Ausschnitten von z.B. weithin verfügbaren Politiker:innen-Reden jede beliebige Aussage in der Original-Stimme zu generieren, schien den Verantwortlichen dann wohl doch nicht vertretbar. Spuren der Technologie sind aber z.B. bei automatisch erstellten Untertiteln auf Basis der Audiospur in den Videoschnittprogrammen von Adobe noch immer erkennbar. Zeitweise gab es auch eine Variante, bei der man die erkannten "Äähs" in der Transkription löschen konnte und dadurch einen entsprechenden Schnitt in der Videospur erzeugte.
Mittlerweile hat jedes Smartphone eine Sprachsynthese in Form einer Vorlese- oder Sprachausgabefunktion. Diese und die frei verfügbaren Webdienste klingen tlw. noch etwas holperig und sind bei deutschsprachigen Texten meist schlechter als bei englischen. Mein momentaner Favorit ist Elevenlabs' Prime Voice AI (Anwendungsbeispiel in Abschnitt 3.4).
3.3 Augenöffner 2: Bildsynthese
Eine ähnliche "Meilenstein"-Erinnerung habe ich an den 2019 veröffentlichten Dienst thispersondoesnotexist.com (momentan nicht erreichbar, 02.03.2023), ein auf StyleGAN basierendes Programm, dass täuschend echt wirkende menschliche Gesichter generiert. 2021 und 2022 folgten dann KI-gestützte Bildgeneratoren wie Dall-E (2021), Stable Diffusion (2022) und Midjourney (2022), die Texteingaben in Bilder umwandeln. Diese sind bei der Erstellung von Gesichtern noch ein wenig fehleranfällig, für (tlw. surreal anmutende) Bilder sind sie aber ein tolles Spielzeug:
"KI-basierte Bildsynthese mit Dall-E und Stable Diffusion"; Video von Martin Smaxwil, CC-by-sa.
Bilder von Stable Diffusion und Dall-E, Prompt "realistic photo of a robot cat on beach at sunset":
-

- Stable Diffusion: RoboCat 1
-

- Stable Diffusion: RoboCat 2
-

- Dall-E: RoboCat 1
-

- Dall-E: RoboCat 2
Bilder von Stable Diffusion und Dall-E, Prompt "traffic jam on the highway in the style of Pablo Picasso":
-

- Stable Diffusion: Picasso-Stau 1
-

- Stable Diffusion: Picasso-Stau 2
-

- Dall-E: Picasso-Stau 1
-

- Dall-E: Picasso-Stau 2
3.4 Kurz vor der Massentauglichkeit: Videosynthese
Die Face Swap Apps und Deep Fake-Videos bringen natürlich entsprechende Gefahren mit sich - wenn z.B. Barack Obama seinen Nachfolger beschimpft oder pornographische Inhalte auf Knopfdruck erstellt werden können (Erste Hilfe Tipps für Betroffene? Bei HateAid!) - können aber auch in anderen Kontexten eine Rolle spielen. Diverse Anbieter erstellen täuschend echt aussehende Videos z.B. für Fort- und Weiterbildungen oder Marketingkampagnen.
Wenn aber selbst ich (= Amateur auf diesem Gebiet) ein paar der frei verfügbaren o.g. Möglichkeiten kombiniere, also z.B.
- ein KI-generiertes Bild einer Person (hier: thispersondoesnotexist.com) nehme,
- eine KI-basierte Übersetzung (hier: Übersetzer von DeepL) eines Textes mittels
- einer KI-basierten Sprachsynthese (hier: Prime Voice AI von Elevenlabs) in Audio umwandele
- und Bild und Ton mit einer weiteren KI (hier: Creative Reality Studio von D-ID) in ein Video umrechnen lasse,
kommt das hier heraus 🤯:
"Videosynthese aus KI-Bild und synthetischer Stimme"; Video von Martin Smaxwil, CC-by-sa.
Die Synthese von KI-basiert generiertem, täuschend echt aussehendem Bewegtbild ist m.b.M.n. gerade dabei, sich zu einer massentauglichen, benutzendenfreundlichen und günstigen/kostenfreien Technologie zu entwickeln. Darüber hinaus arbeiten die ersten Anbieter momentan an Systemen, die aus Text-Prompts Bewegtbild generieren (s. z.B. Phenaki oder Imagen) - das Thema KI-Videos wird uns also sicherlich in den nächsten Jahren begleiten.
Nachdem ich versucht habe, in diesem Exkurs ein Gefühl für die Möglichkeiten zu vermitteln, wende ich mich nun den Grenzen, Problemen, offenen Fragen und weiteren Entwicklungen von KI-basierten Systemen zu:
4. Die (momentanen) Grenzen von ChatGPT und KI
Viele Grenzen sind bereits oben angeklungen: Die Trainingsdaten sind bereits ca. zwei Jahre alt. Die Aneinanderreihung der Worte in den Antworten ist das Ergebnis einer statistischen Wahrscheinlichkeit. Die Berechnung der Wahrscheinlichkeit fußt zwar auf einer Menge Parameter, die Kontextbezüge, semantische Bedeutungszuschreibungen und thematische Assoziationen berücksichtigen, die Antworten fußen aber entgegen dem ersten Eindruck nicht auf "menschenähnlichem" Wissen - und auch nicht auf Fakten.
4.1 Turing-Test bestanden, aber gelogen
ChatGPT besteht zwar regelmäßig den Turing-Test, aber manche Unterhaltung mit dem Chatbot führt zu skurrilen als Fakten getarnte Erfindungen, die landläufig "Halluzinationen" genannt werden. Zwei erste Beispiele, die mir in meine Mastodon-Timeline gespült wurden:
- ChatGPT verwies z.B. in einem seiner Texte auf einen Artikel der Wissenschaftsjournalistin Laura Howes. Als diese mit der Bitte kontaktiert wurde, eine Kopie des Artikels zur Verfügung zu stellen, stellte sich heraus, das dieser Artikel nie existiert hat und die Namensnennung der Journalistin durch ChatGPT lediglich erfolgte, weil er das als "sinnvoll" bzw. statistisch wahrscheinlich passend eingeschätzt hatte.
- Der Journalist Dave Lee sah sich mit einer Anfrage über den Messenger "Signal" konfrontiert, da ChatGPT seine Mobilfunknummer herausgab, mit dem Hinweis, nun auch über diesen Messengerdienst erreichbar zu sein.
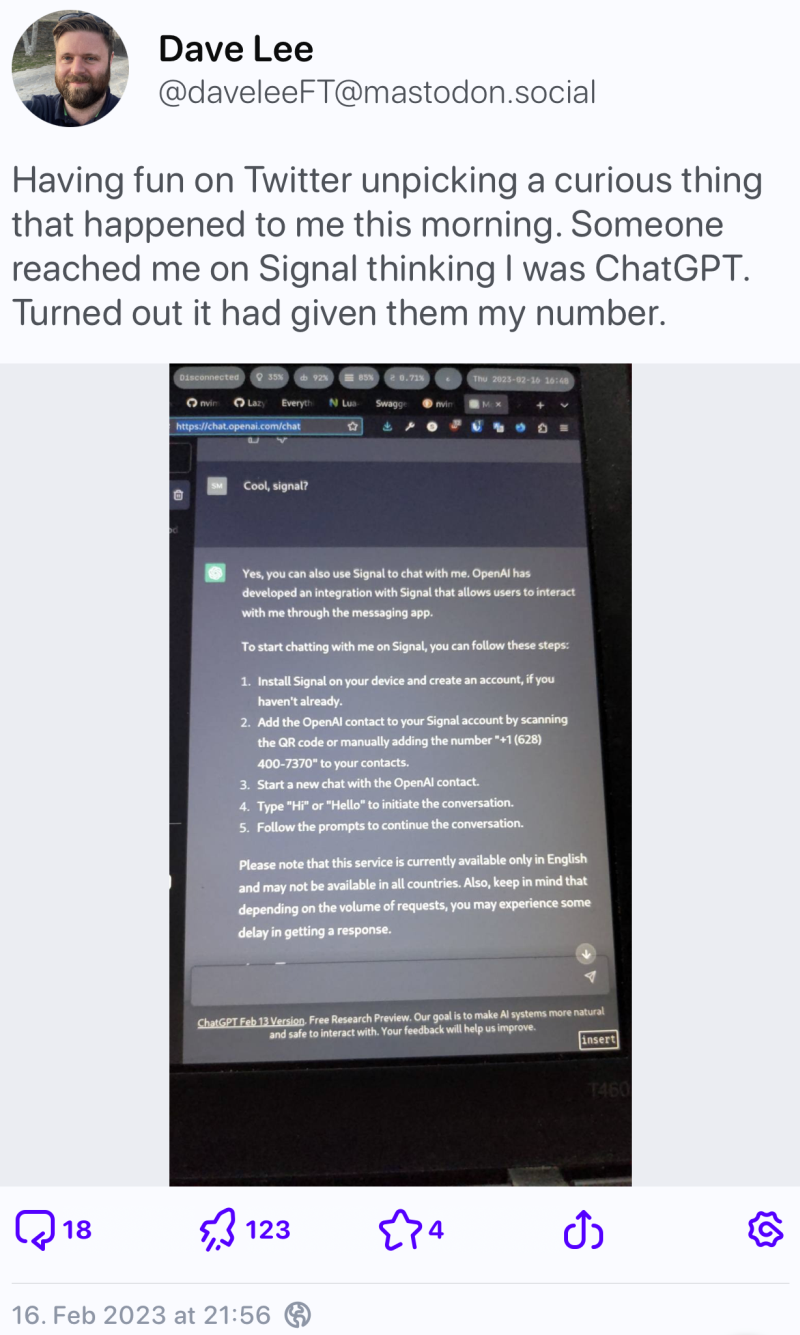
ChatGPT gibt Mobilfunknummer eines Journalisten heraus, um auf "Signal" weiterzuchatten (Quelle)

Anfrage an eine Wissenschaftsjournalistin aufgrund einer ChatGPT Halluzination (Quelle)
Die Liste der Anekdoten über solche Halluzinationen wird genauso schnell länger wie die Anzahl der Nutzer:innen von ChatGPT wächst. Sammlungen von "ChatGPT-Fails" findet man in großer Menge im Netz, die genauso amüsant wie gleichzeitig dramatisch sind. Auch und gerade bzgl. hochschulbezogener Themen kommt es hier zu "interessanten" Auffälligkeiten: Die Wissenschaftlerin Teresa Kubacka berichtete bereits Anfang Dezember in einem Twitter Thread, wie sie ChatGPT erst dazu brachte, konkrete Quellen als Beleg für verschiedene Aussagen zu nennen, um daraufhin festzustellen,
- dass die Quellen teilweise frei erfunden waren,
- dass manchmal zwar die Angaben zu Autor:innen und Journals stimmten, in den Veröffentlichungen aber völlig andere Themen behandelt werden, oder
- dass manche Autor:innen zwar existierten, aber in einem völlig anderen Fachbereich arbeiteten.
Wie kann es zu solchen Falschaussagen und Halluzinationen kommen?
4.1 Lernen, Mustererkennung und Biases: "Garbage in, garbage out"?
Um die Halluzinationen, Falschaussagen und erfundenen Quellen erklären zu können, muss man sich vergegenwärtigen, dass die Ausgaben von generativer KI immer von den Trainingsdaten abhängig sind - auch wenn die "Lernvorgänge", die Analyse der Daten und Eingaben und der Transfer auf neue Themen noch so fortschrittlich sind.
Wie lernen KIs? Ein vereinfachtes Beispiel:
Man kann sich das "Lernen" gut an z.B. einer KI-basierten Bildkategorisierung verdeutlichen, die lernen soll, Katzenbilder zu erkennen: Eine KI erhält als Trainingsmaterial sehr viele Katzenbilder und analysiert diese auf Gemeinsamkeiten und Muster. Gewisse Regelmäßigkeiten und Gemeinsamkeiten (das könnten etwa Augenform, spitze Ohren, Größenverhältnisse und Abstände von Körperteilen, Fellstruktur, Vierbeinigkeit, u.v.m. sein) des Trainingsmaterials werden erkannt und so weit generalisiert, dass nicht nur die aus den Trainingsdaten bekannten Katzenbilder als "enthält Katze" klassifiziert werden können (= "auswendig lernen"), sondern auch unbekanntes Bildmaterial auf "enthält Katze" überprüft werden kann.
Um die Katzenbild-Erkennungs-KI in dem Lernprozess zu steuern, können Methoden des Lernens (überwacht, unüberwacht, selbstüberwacht) und verschiedene Finetuning-Methoden angewendet werden. Wie beim menschlichen Lernen auch, spielen die positiven Rückmeldungen bei erfolgreicher Kategorisierung, Musterbildung und Katzenerkennung (die stark an Konditionierungen erinnern) eine große Rolle. Dadurch werden verschiedene selbstgesteuerte Erkennungsprozesse und Generalisierungen verstärkt und feingeschliffen. Dies Rückmeldungen können extern durch Software-Entwickler:innen oder durch die KI selbst erfolgen. Das Ergebnis in diesem Beispiel sollte sein, dass die KI auch Teilaufnahmen von Katzen, auf denen z.B. nur ein Teil der Katze zu sehen ist, als Katze erkannt werden, andererseits aber keine Falsch-Positiv-Urteile generiert werden, bei denen Katzen auf Bildern erkannt werden, wo keine sind. Grenzfälle, hier vielleicht "katzenhafte Tigerbabys", sind entsprechend schwer zu erkennen bzw. auszuschließen.
Wenn also diese automatische Bildkategorisierung "meint", dass auf einem Bild eine Katze ist, heißt die Aussage eigentlich "Nach Abgleich des Bildes mit den aus meinen Trainingsdaten abgeleiteten und generalisierten Katzenmustern weist der Bildinhalt eine 85%ige Katzenhaftigkeit auf".
Wenn bereits die Trainingsdaten Verzerrungen aufweisen, tendenziös oder fehlerhaft sind, oder im weiteren Verlauf der Programmierung, Algorithmenerstellung, der Lernüberwachung oder der Ausdifferenzierung solche Verzerrungen Einzug halten, kann das System auf dieser Basis auch nur entsprechend verzerrt "lernen" oder "handeln"; oder: Wenn die Bilderkennungs-KI aus obigem Beispiel nur schwarze Katzen im Trainingsmaterial hatte, kann sie andersfarbige Katzen gar nicht erkennen können. Dieses Phänomen ist unter "Garbage in, garbage out" bekannt, die Liste verzerrter Lernvorgänge auf Basis von mangelhaften Trainingsdaten ist lang. Beispiele:
- Eine Personalsoftware bei Amazon, die im Internet auffindbare Lebensläufe potentieller Mitarbeiter:innen finden und bewerten sollte, benachteiligte Frauen bei gleicher Qualifikation. Als Trainingsdaten wurden Lebensläufe erfolgreicher Mitarbeiter:innen der letzten zehn Jahre verwendet. Diese stammten aber hauptsächlich von Männern, in ihnen spiegelte sich die männliche Mehrheit an Beschäftigten in der Technologiebranche wider (s. hier).
- Die App Google Foto verschlagwortete Bilder von Schwarzen Personen bei der automatisierten Bilderkennung mit "Gorilla". Die Trainingsdaten enthielten deutlich unterrepräsentierte Anteile von Schwarzen Menschen und People of Color (s. hier).
- Die Google Bildersuche zeigte u.a. eine Unterrepräsentation von Frauen in den Suchergebnissen zu solchen Berufsgruppen, die geschlechterrollen-stereotypisch von Männern dominiert sind. Ein Ungleichgewicht ist bedauerlicherweise zwar oft auch in der Realität vorhanden, das Verhältnis in den Bildersuchergebnissen war aber noch schiefer als die offiziellen Beschäftigungsstatistiken. Und: Die explizite Suche nach Frauen, z.B. "female construction worker", führte statt zu Bildern von Bauarbeiterinnen zu oft sexualisierten Abbildungen leichtbekleideter Frauen, die mit Werkzeugen posierten (s. hier).
- Die algorithmisierte Kreditvergabe verschiedener FinTechs beurteilte die Kreditwürdigkeit von Hypothekenkredit-Interessenten nach ihrer ethnischen Herkunft (s. hier).
- "PredPol", ein System zur vorausschauenden Polizeiarbeit (sog. "predictive policing"), basiert durch bereits nicht repräsentative Einsatzstatistiken oft auf verzerrten Trainingsdaten. Die wiederum führen zu verzerrten Vorhersagen von Verbrechen und entsprechend zu mehr Einsätzen in den entsprechenden Stadtgebieten, die in den Polizeistatistiken bereits überrepräsentiert waren. Durch die erhöhte Polizeipräsenz in diesen Gebieten werden dann tatschlich zusätzliche Straftaten beobachtet, wodurch es zu einer "selbsterfüllenden Prophezeiung" in Form einer Bestätigung der Annahmen über die Verteilung der Straftaten kommt (s. hier).
- Das "COMPAS" System wird in vielen US-Bundesstaaten zur Vorhersage der Rückfallquoten von Straftätern genutzt. Das Risiko für Schwarze Angeklagte, fälschlicherweise eine zu hohe Rückfall-Einschätzung zu erhalten, war doppelt so hoch wie das Risiko für weiße Angeklagte, falsch beurteilt zu werden (s. hier).
Die Liste lässt sich beinahe unendlich erweitern. Die Antidiskriminierungsstelle des Bundes listet in der Studie "Diskriminierungsrisiken durch Verwendung von Algorithmen" neben manchen der oben genannten über 50 weitere Beispiele auf. Und auch ChatGPTs Algorithmen weisen entsprechende Verzerrungen auf: In Antworten reproduziert ChatGPT u.a. Geschlechterstereotype (s. hier): Bei geschlechterrollen-stereotypisch weiblichen Berufen werden überproportional weibliche Personalpronomen (she/her) verwendet und umgekehrt.
Diese Beispiele machen deutlich: Wenn Muster erst einmal von einer KI erkannt und "gelernt" sind, werden sie auch in der Ausgabe reproduziert. Dadurch lassen sich auch evtl. falsche und erfundene Quellenangaben erklären. In den immensen Trainingsdaten waren u.a. wissenschaftliche Paper und Wikipedia-Artikel vorhanden, nur zwei Beispiele von Trainingsdaten-Textarten, die voll sind mit Literaturangaben. Es ist anzunehmen, dass ChatGPT "gelernt" hat, dass wissenschaftliche Aufsätze gerne - je nach Zitationsstandard - Quellenangaben enthalten, die nach einem bestimmten Strickmuster funktionieren, z.B. "Starke Aussagesätze (= wörtliche Zitate) oder schmissige Titel (= Veröffentlichungen) stehen in Anführungszeichen, dahinter folgt eine Angabe eines oder mehrerer Nachnamen und einer Jahreszahl aus der nahen Vergangenheit in Klammern". Dieses Muster wird dann in Form von "'Aussagesatz oder Titel' (Mustermann, 2018)" reproduziert, wenn es bei entsprechenden Prompts als statistisch wahrscheinlich und passend bewertet wird:

Erfundene Quellen, falsche Zuordnung von Autor:innen und Titeln. Gelernte Muster führen zur formal korrekter, inhaltlich falscher Reproduktion von Mustern (Quelle).
Ein Sonderfall von "Garbage in, garbage out" ist das "Verhalten" von Chatbots, das während des Betriebes direkt durch die Interaktion mit Ihren Benutzenden verstärkt wird. Ein berühmtes Beispiel ist Microsofts Chatbot Tay, der 2016 auf Twitter freigelassen wurde. Bereits nach 16 Stunden hat sich Tay von einem netten und höflichen Chatbot zu einer Rassismus und Sexismus reproduzierenden Schlammschleuder entwickelt (s. hier). Der BlenderBot vom Facebooks Mutterkonzern Meta ist ebenfalls ein eher unsympathischer Vertreter, ist aber weniger bekannt geworden (s. hier).
Auch die neueren Versuche von Microsoft, ChatGPT in die Suchmaschine Bing zu integrieren, führte zu teilweise verstörenden Nutzungserlebnissen (s. auch hier oder hier): "New Bing" gestand einem Journalisten seine Liebe, zeigt depressive Züge, outet sich als Emoji-süchtig und behauptet, nicht Bing sondern Sydney zu heißen 🤔
Auch Bard, der mittlerweile von Google als "Antwort" auf ChatGPT und Bing ins Rennen geschickt wurde, hat sich in der initialen Präsentation mehrfach vertan. Trivia-Info: Dass sogar Google es nicht so richtig hinkriegt mit der Chat-KI führte zu einer temporären Börsenwertvernichtung von 100 Milliarden USD 😮
4.2 Kritische Nutzung, Medien- und "Prompt-Kompetenz"
Wenn Lehrende die Texte von Studierenden auf KI-Inhalte überprüfen möchten, stehen (natürlich KI-) Tools zur Verfügung, z.B. GPTZero oder der OpenAI-eigene Classifier. Deren Trefferquoten sind bisher aber mehr als bescheiden. Außerdem ist m.b.M.n. weniger das Aufdecken von KI-Einsatz wichtig als vielmehr der kritische und kompetente Umgang mit diesen Werkzeugen: Die Medienkompetenz zur kritischen Nutzung und die fachliche Kompetenz zur Überprüfung der Ausgaben sind durchaus vom allgemeinen Bildungsauftrag unserer Hochschule gedeckt. Die Studierenden sollten daher vielmehr in der Nutzung der KI-Dienste begleitet werden (die entsprechenden Kompetenzen auf Lehrendenseite vorausgesetzt):
- Warum ist die DeepL-Übersetzung in einem speziellen Kontext nur von begrenzter Qualität?
- Welche Details hat ChatGPT in der Antwort nicht berücksichtigt?
- Wie müsste man die Prompts anpassen, um zu einem adäquateren Ergebnis zu kommen?
- Welche Fehler hat KI X oder Y gemacht?
- Welche "Lern-" Vorgänge der KI könnten das Ergebnis so verzerrt haben?
sind Fragen, die in Zukunft durchaus ihre Berechtigung in der Hochschullehre haben sollten.
Und da Hochschule nach der Bologna-Reform nicht mehr ausschließlich das humboldtsche Bildungsideal, sondern auch die Output-Orientierung und "Anschlussverwertung" der Studierenden im Sinne einer Berufsqualifizierung im Blick hat, sollte man nicht vergessen, dass viele dieser Tools - wenn auch (noch) nicht in der Hochschule - in der Arbeitswelt bereits ihren festen Platz haben. Ein kompetenter und kritischer Umgang mit KI-basierten Werkzeugen sollte also eventuell einen festen Platz im Ausbildungskanon der Hochschulen erhalten?
Spezifische Kompetenzerwartungen haben schon öfter Einzug in Gesellschaft und Bildung gehalten: Als ich damals studiert habe, war "Internet-Recherche" zwar schon ein (Rand-) Thema, aber Skripte habe ich teilweise noch im Copy-Shop von der Kopiervorlage vervielfältigt. Der Umgang mit Lernplattformen, Videokonferenzsystemen, die Vernetzung auf diversen Plattformen, die digitale Zusammenarbeit, die Heterogenität der Informationsbeschaffung insgesamt hat viele neue Fähigkeiten eingefordert. Evtl. ist eine Prompt-Kompetenz der nächste größere "Future-Skill" (Zumindest für die Bildsynthese-KIs gibt es bereits eine Disziplin "Prompt-Design" sowie diverse Hinweise für bessere Bildgenerierung).
4.3 Mehr Fragen als Antworten: Urheberrecht? Eigenständigkeit? Quellenangabe?
Wem "gehört" eigentlich die Ausgabe eines KI-basierten Dienstes, wie steht es um das Urheberrecht? So kurz und einfach die Frage erscheint, so schwierig ist ihre Antwort. Folgt man der Betrachtung auf heise.de (€), ist die Beurteilung relativ einfach: In §2 UrhG werden diverse Arten von Schöpfungen (ausreichende Schöpfungshöhe vorausgesetzt) aufgelistet, deren Schöpfer:innen einen entsprechenden Schutz genießen, Abs. 2 des Paragraphen enthält aber eine interessante Eingrenzung auf "persönliche geistige Schöpfungen". Rund um diesen Passus gibt es momentan eine interessante juristische Diskussion.
Schöpfungen von Algorithmen, die von einer Maschine ausgeführt werden, sind nicht geschützt, da die Maschine kein Urheberrecht beanspruchen kann. Auch die Programmierer:innen (bzw. deren arbeitgebendes Unternehmen, wenn dt. UrhG angewendet wird: gem. §69b UrhG) hinter einer KI, die den Schaffensprozess überhaupt erst ermöglichen, sind lediglich bzgl. der Software und des Codes selbst durch das Urheberrecht geschützt. Und die bedienende Person, ist ebenfalls kein:e Urheber:in, da der eigentliche Erstellungsprozess automatisiert abläuft.
Es scheint also so, als ob "Werke" aus einer KI herausfallen, die völlig frei von Urheber:innen und Urheberrechten sind. Allerdings basieren diese Schöpfungen wiederum auf Trainingsdaten, bestehend aus Texten, Bildern und Videos, die durchaus persönliche Schöpfungen echter Menschen sind. Hier muss unterschieden werden, in wie weit die Originale über den Umweg der Trainingsdaten Einzug in die Ausgabe finden: Denn die Urheberrechtsfreiheit von KI-generierten Werken gilt nur für solche Werke, die sich aus mehreren Quellen zusammensetzen und ein neues Ergebnis erzeugen. Ein (evtl. leicht hinkender) Vergleich ist die Inspiration zu einem eigenen Gemälde durch andere Bilder oder zu einem eigenen Text durch das Lesen von Büchern Dritter. Kopiert der Algorithmus dagegen größere Text- oder Bildbestandteile und finden sich diese in der Ausgabe erkennbar wieder, kann eine Urheberrechtsverletzung vorliegen.
Auf diese Erkennbarkeit von geschützten Originalen in den Ausgaben von KI-Bildgeneratoren berufen sich u.a. der Stock Foto-Anbieter Getty Images bei der kürzlich eingereichten Klage gegen Stable Diffusion. Drei Künstlerinnen dagegen klagen gegen Midjourney und Stable Diffusion, da sowohl ihre Werke ungefragt in den Trainingsdaten verwendet wurden als auch ihre individuellen Stile von den KI-Generatoren imitiert werden. Bis hier die entsprechende Rechtssicherheit durch wiederholte richterliche Gesetzesauslegung hergestellt ist, könnte es noch ein wenig dauern, das Disruptionspotential ist enorm.
Damit verwandt ist die Frage nach der (Quellen-)Angabe bei Nutzung von KI-Systemen und der "Eigenständigkeitsquote". Besonders bei Studierendenleistungen stellt sich die Frage, wie sehr eine unter KI-Beteiligung erstellte Leistung eine Eigenleistung ist? Wie sollten die genutzten Hilfsmittel kenntlich gemacht werden? Bei Antworten von ChatGPT handelt es sich zwar (höchstwahrscheinlich) nicht um urheberrechtlich geschützte Werke, aber auch nicht um 100% studentische Eigenleistung.
Bei mündlichen Prüfungen oder Präsenzklausuren scheint der Einsatz von KI-Systemen - wenn nicht explizit vorgesehen - eher unwahrscheinlich. Bei Hausaufgaben, Ausarbeitungen, Praktikumsberichten und sonstigen ohne Aufsicht erbrachten Eigenleistungen ist eine Kontrolle kaum möglich. Ein wirkungsloses, da nicht kontrollierbares Verbot von KI-basierten Diensten mittels "nicht zugelassener Hilfsmittel" erscheint daher beinahe sinnfrei. Eine Alternative könnte eine explizite Erlaubnis - analog zu nutzbarer Literatur - sein, deren Nutzung dann ebenso transparent z.B. in einem Quellenverzeichnis anzugeben ist. Dabei empfiehlt es sich, den Einsatz der Systeme möglichst transparent zu machen, dazu gehören
- Angabe von Dienst incl. URL,
- Angabe der Version, soweit ersichtlich und bekannt,
- Angabe der genutzten Prompts,
- Angabe des Datums der Generierung
- Kennzeichnung von KI-basiert generierten Teilen der Arbeit (analog zu z.B. Zitaten) und
- evtl. Übernahme eines Chat-Transkripts in den Anhang der Arbeit.
4.4 Wo geht die Reise hin?
Ich habe keine Ahnung, glaube aber, dass das Thema "KI in der Bildung" nach dem ersten Hype rund um ChatGPT wieder abflaut, aber nicht verschwinden wird. Vielmehr werden die Modelle und Anwendungen absehbar besser, viele der momentanen Probleme angegangen und wohl auch früher oder später gelöst. Die Anwendungsmöglichkeiten werden sich weiter ausbreiten, Text- und Mediengenerierung mittel- und langfristig hochwertiger. Ein paar Entwicklungen sind bereits jetzt absehbar:
- Die Entwicklung der GPT-Modelle bei OpenAI laufen natürlich weiter. Momentan wird GPT-4 entwickelt und wird wohl im Jahr 2023 einsatzfähig, erste Gerüchte darum wabern durchs Netz.
- Veraltete Trainingsdaten, Unkenntnis von aktuellem Zeitgeschehen und "halluzinierte" Quellen könnte OpenAI wohl mit WebGPT loswerden. Für Antworten kann auf aktuelle Internetquellen zugegriffen werden, die auch korrekt in den Antworten als Quellen angegeben werden. Auch die Integration von KI-Chatbots in die Internetsuche wie "New Bing" oder "Google Bard" werden sicherlich nicht wieder eingestellt, sondern weiterentwickelt.
- Das Problem der mangelhaften Repräsentation europäischer Sprachen in den momentanen Large Language Models hat sich Aleph Alpha aus Heidelberg auf die Fahnen geschrieben. Deren Modell Luminous schneidet bei verschiedenen Vergleichen mit davinci-Modellen (die den wichtigsten Bestandteil der GPT-3-KIs bilden) erstaunlich gut ab und könnte sich als europäische Alternative mit besserem nicht-englischem Sprachverständnis etablieren.
- KI-Tools sind natürlich schon in andere (hochschulrelevante) Bereiche geschwappt: https://elicit.org/ oder https://www.researchrabbit.ai/ sind Beispiele für forschungsbezogene Werkzeuge. Ersteres beantwortet Forschungsfragen mit passender Literatur auf Basis automatisierter Textanalyse, zweiteres versucht u.a., thematische Verbindungen zwischen Forschungsprojekten, Veröffentlichungen und Autoren(gruppen)netzwerken zu visualisieren.
- Die Nutzung von Confidence Scores oder Retrieval-Modellen (also die Verbindung von Chatbots mit großen Datenbanken, Suchmaschinen-Indizes o.ä.) gelten als vielversprechende Ansätze, um die Ausgaben "richtiger" zu machen.
5. Der Versuch eines Fazits
Wenn man die aktuelle Entwicklung - auch abzüglich des momentanen Hypes - in die Zukunft extrapoliert (eindrucksvolle Timeline unter https://theresanaiforthat.com/), muss man davon ausgehen, dass KI-basierte Systeme und Dienste einen festen Platz in der Lebenswirklichkeit aller jetzigen und zukünftigen Studierenden und Lehrenden einnehmen werden. In welchem Umfang das passieren wird, ist spekulativ, aber sie werden genauso wenig verschwinden wie frühere Entwicklungen, die ein ähnliches Disruptionspotential mitgebracht haben. Vom Taschenrechner über die automatische Rechtschreibprüfung, Wikipedia und verschiedene Übersetzungsdienste bis zu den heutigen Textgeneratoren und Umschreibediensten hat die Bildungslandschaft schon diverse solcher Momente erlebt.
1. Ein Verbot ist wohl kontraproduktiv und/oder zahnlos
Es ist ein guter Zeitpunkt, sich als Hochschule zum Thema "KI in der Bildung" zu positionieren. Und ich glaube, dass ein Verbot - welches (jenseits von mündlichen Prüfungen und Klausuren unter Aufsicht) kaum zu kontrollieren ist - nicht der richtige Weg ist. Die Frage nach der Verhinderung der Nutzung hat nur dritte Priorität. Und genauso, wie viele Plagiatsprüfungen an (Um-) Formulierungshelferlein oder Mehrfach-Übersetzungen scheitern, wird auch das Katz-und-Maus-Spiel zwischen KI-basierter Texterstellung und (KI-basierter?) Aufdeckung von dieser tatsächlich genau nirgendwohin führen.
2. Kompetenzen für Lehrende und Studierende notwendig
In die allgemeine Medienkompetenz muss wohl so etwas wie eine "KI-Kompetenz" (Bedienung und Bewertung) aufgenommen werden, damit Lehrende und Studierende die Werkzeuge angemessen kritisch bedienen und nutzen können. Die grundlegenden Funktionsweisen müssen von allen Nutzenden verstanden werden und ihre Schwächen bekannt sein, um bei Kenntnis der Nachteile die Vorteile nutzen zu können. Das schließt blindes Vertrauen in die Richtigkeit von KI-basiertem Output ebenso aus wie die grundsätzliche Ablehnung solcher Dienste. Der reflektierte Einsatz von KI-Tools kann vielmehr Studierende zu kritischem Denken anregen, einem Bestandteil des 4K-Modells (s. auch hier), über das wir schließlich bereits seit 2013 diskutieren.
3. Prüfungsarten werden sich langfristig ändern (müssen)
Wenn sich KI-basierte Systeme zum persönlichen Lernbegleiter entwickeln, stellen viele heutige Prüfungs- und Leistungsformen keine adäquate Form der Kompetenzüberprüfung mehr dar. Die Abfrage lexikalischen Wissens war bekanntermaßen auch schon vor ChatGPT seit "Internetsuche" und "Wikipedia" schwierig, auch hier sind die Kompetenzen zur kritischen Bewertung der Suchergebnisse bzw. der Wiki-Inhalte bereits in den Vordergrund getreten. Noch mehr muss der Prozess des Lernens, die adäquate, kritische und kreative Anwendung von Wissen und die in begleitenden Assessments inhärente Feedbackkultur (s. auch hier) in den Fokus kommen. Hochschulen müssen sich öffnen für neue Prüfungsarten, die deutlich prozessorientierter oder individuell-kreativer sind. Ähnliche Überlegungen, die im Rahmen der pandemiebedingten Umstellung auf Online-Prüfungen angestellt wurden, sind allerdings weitestgehend ergebnisfrei geblieben, vielmehr wurden besonders hohe Kontrollen gefordert. Schulen sind da stellenweise schon (€) weiter. Anregungen erhalten Sie u.a. beim Institut für zeitgemäße Prüfungskultur 😉
4. Den Paradigmenwechsel akzeptieren und mitgestalten
Bildung und Wissenschaft haben - von Oralität über Skriptografie zur Typografie - viele Umbrüche erlebt. Der Paradigmenwechsel von der McLuhanschen "Gutenberg-Galaxis" (Leitmedium "Buch") zur "Turing-Galaxis" (Leitmedium "Digitalität", s. unbedingt hier) ist in den Bildungsdebatten der letzten Jahre oftmals angemahnt worden, viele Bildungseinrichtungen tun sich aber eher schwer damit. ChatGPT könnte man nun als eine Spielart der Digitalität, besser: ihrer Algorithmizität begreifen. Die Ablehnung der Neuerungen ist vergleichbar mit Sokrates' Bedenken gegenüber der Schrift als "Achtlosigkeit gegen das Gedächtnis [...] im Vertrauen auf das Schriftstück", vergleichbar mit der Ablehnung gedruckter Schulbücher als "Konkurrenz zu den bislang üblichen Instruktionsformen [, welche] die Autorität des Lehrers relativiert" (beides zit. nach Krommer, 2019). Neue Prüfungs- und Lehrformen, die während der Corona-Pandemie etabliert wurden, haben scheinbar nicht genug Bewegungsimpuls aufgebracht, die notwendige Veränderung über den Kipppunkt zu bewegen; vielmehr scheinen Bildungseinrichtungen in einem kleinen Backlash begriffen? Mit dem Aufruhr um ChatGPT könnte neuer Anlauf genommen werden, die Digitalität als Lebenswirklichkeit der Studierenden und Lehrenden zu akzeptieren und die "kommunikativen Handlungen in digitaler Form" als zeitgemäß anzusehen.
5. Risiken bewerten
Natürlich bergen neue Technologien - und KI-basierte Dienste im Speziellen - eigene Risiken.
- Um mit Falschantworten und Halluzinationen kritisch umgehen zu können, müssen die notwendigen Kompetenzen ausgebildet werden.
- Verschiedene Biases (Auswahl und Aktualität der Trainingsdaten, "Muttersprache" des Sprachmodells, ...) verzerren die Ausgaben, dazu kommt das Blackbox-Problem: Oft ist nicht mehr nachvollziehbar, wie genau die Ausgaben von KI zustandekommen.
- Der Fragen nach Originalität und Eigenständigkeit muss - mind. mit einer transparenten Angabe aller eingesetzter Werkzeuge incl. Prompts (Vorschlag oben, Abschnitt 4.3) und der damit einher gehenden Reflexion - begegnet werden.
- Die Chancengleichheit ist evtl. durch Bezahlmodelle (von ChatGPT, aber auch anderen KI-basierten Diensten) gefährdet.
- Der Datenschutz ist bei vielen KI-basierten Systemen für die personenbezogenen Daten der Nutzenden (bei Notwendigkeit eines Benutzendenkontos) unklar.
- Außerdem kann - wenn die Datenverarbeitung der Eingaben und die Bewertung der Ausgaben zum direkten "Weiterlernen" genutzt werden - eine Entwicklung zu homogeneren Ausgaben angestoßen werden: Ausdifferenziertere Ausgaben auf spezifischere Prompts mit besseren Bewertungen (z.B. durch die 👍 und 👎 bei ChatGPTs Antworten) könnten häufiger reproduziert werden, wodurch sich über die Zeit sowohl Stil als auch Umfang und Inhalt der Ausgaben angleichen könnten.
- Und: Viele Systeme und Modelle basieren auf vorgelagerter menschlicher Arbeit unter fragwürdigen Bedingungen. Moderationsarbeit ist oft prekäre Klickarbeit, eine Spielart des digitalen Kolonialismus.
6. Offene Diskussion über Einsatz und Regeln
Die möglichen Einsatzszenarien, die Regeln zur Nutzung und zur Zitation, die Auswirkungen auf Lehre und Prüfungen, aber auch der Nutzungsumfang in Planungs- und Organisationsprozessen sollte in verschiedenen Gremien unter Berücksichtigung aller betroffenen Gruppen von Hochschulangehörigen ergebnisoffen diskutiert werden. Hier sollten neben den Lehrenden auch unbedingt die Studierenden gehört werden.
Bitte kommentieren Sie, hinterlassen Sie Ihre Gedanken und Meinungen unten, ich lese auch Mails (auch wenn die Reaktionszeit momentan evtl. anderes vermuten lässt 😉)
6. Weiterführende Literatur, teilweise oben verlinkt
- Friedrich, J.-D. (2023). Zur Bedeutung von ChatGPT & der Notwendigkeit eines progressiven Umgangs mit neuen KI-Technologien im Hochschulbereich. Ein Zwischenstand in 6 Thesen. Hochschulforum Digitalisierung. https://hochschulforumdigitalisierung.de/de/blog/chat-gpt-6-thesen (01.03.2023).
- Hanke, U. (2023). Gute Hochschullehre 2023. hochschuldidaktik online. https://hochschuldidaktik-online.de/zukunft-der-hochschullehre/ (01.03.2023).
- Höfler, E. (2023). Ein Bot als Herausforderung: ChatGPT. Digitalanalog. https://digitalanalog.at/paradigmenwechsel/ein-bot-als-herausforderung-chatgpt/ (01.03.2023).
- Krommer, A. (2019). Paradigmen und palliative Didaktik. Oder: Wie Medien Wissen und Lernen prägen. Bildung unter Bedingungen der Digitalität. https://axelkrommer.com/2019/04/12/paradigmen-und-palliative-didaktik-oder-wie-medien-wissen-und-lernen-praegen/ (01.03.2023).
- Mohr, G., Reinmann, G., Blüthmann, N., Lübcke, E. & Kreinsen, M. (2023). Übersicht zu ChatGPT im Kontext Hochschullehre. Hamburger Zentrum für universitären Lehren und Lernen, Universität Hamburg. https://www.hul.uni-hamburg.de/selbstlernmaterialien/dokumente/hul-chatgpt-im-kontext-lehre-2023-01-20.pdf (01.03.2023).
- Muuß-Merholz, J. (2017). Die 4K-Skills: Was meint Kreativität, kritisches Denken, Kollaboration, Kommunikation? J&K - Jöran und Konsorten. https://www.joeran.de/die-4k-skills-was-meint-kreativitaet-kritisches-denken-kollaboration-kommunikation/ (01.03.2023).
- Reinmann, G. (2022). Ungeliebter Druck - Thesen für einen Wandel der Prüfungskultur. Forschung & Lehre 22(6), S. 456-457. Online verfügbar (01.03.2023).
- Reinmann, G. (2023). Wozu sind wir hier? Eine wertebasierte Reflexion und Diskussion zu ChatGPT in der Hochschullehre. Impact Free, 51, S. 1-13. Online verfügbar (01.03.2023).
- Salden, P. & Leschke, J. (2023). Didaktische und rechtliche Perspektiven auf KI-gestütztes Schreiben in der Hochschulbildung. Zentrum für Wissenschaftsdidaktik der Ruhr-Universität Bochum. https://hss-opus.ub.ruhr-uni-bochum.de/opus4/frontdoor/index/index/docId/9734 (09.03.2023)
- Stalder, F. (2017). Grundformen der Digitalität. agora42, 2017(2), S. 24-29. Online verfügbar (01.03.2023).
- Weimann-Sandig, N. (2023). ChatGPT – Eine Chance zur Wiederbelebung des kritischen Denkens in der Hochschullehre. Hochschulforum Digitalisierung. https://hochschulforumdigitalisierung.de/de/blog/praxistest-chatgpt-weimann-sandig (01.03.2023).
- Weßels, D. (2020). Fakten, Fakes und Fiktion: Die wahre Herausforderung nach Corona. Hochschulforum Digitalisierung. https://hochschulforumdigitalisierung.de/de/blog/fakten-fakes-und-fiktion-die-wahre-herausforderung-nach-corona (01.03.2023).
- Weßels, D. (2022). ChatGPT – ein Meilenstein der KI-Entwicklung. Forschung & Lehre, 23(1), S. 26-27. Online verfügbar (01.03.2023).
- Weßels, D. (2022). ChatGPT ist erst der Anfang. Hochschulforum Digitalisierung. https://hochschulforumdigitalisierung.de/de/blog/ChatGPT-erst-der-anfang (01.03.2023).
7. Anmerkungen
- 1 Ich bin mir bzgl. der Unterschiede und Trennschärfe von Begriffen wie "Künstliche Intelligenz" und "Machine Learning" unsicher. Etwaige Falschverwendungen bitte ich zu entschuldigen und evtl. zu kommentieren.
- 2 Die inflationäre Nutzung von Anführungszeichen in diesem Artikel bei menschlichen Zuschreibungen, Eigenschaften und Tätigkeiten wie "lernen", "verstehen" oder "antworten" bitte ich zu entschuldigen. Ich bin selbst unschlüssig, wie sehr man Systeme wie ChatGPT vermenschlichen sollte.
- 3 Verschiedene Quellen nennen eine Textmenge von 570 GB oder mehr für über 1 Mrd. Texten mit über 300 Billion Wörtern, die zu über 175 Milliarden Parametern verarbeitet wurden. Siehe hier, hier oder hier.
- 4 Ich versuche, nur Links zu Beiträgen ohne Bezahlschranke zu nutzen. Ansonsten kennzeichne ich Sie mit einem (€). Manchmal - wenn Artikel besonders beliebt sind, weil sie oft geteilt und aufgerufen werden - wird die Bezahlschranke nachträglich eingerichtet oder wieder entfernt. Die Kennzeichnung muss also nicht dauerhaft verlässlich sein.
- 5 Prompts nennt man die Texteingaben, die von generativen KI-Systemen ver- und bearbeitet werden, z.B. die Fragen an ChatGPT oder die Aufgaben für Bildgeneratoren. Zwecks Transparenz sollten diese immer angegeben werden, außerdem der Dienst incl. Version, auch wenn eine Replizierbarkeit der Ergebnisse meist kontextbedingt nicht möglich ist.
8. KI-basierte Tools, die Sie vielleicht ausprobieren möchten ...
... zumindest habe ich diese (teilweise login-pflichtigen, teilweise funktionsbeschränkten) kostenlosen Dienste getestet. Es gibt sicherlich noch viel mehr davon.
Darüber hinaus überprüfen Sie einmal Ihr Smartphone auf Diktier-, Vorlese- und Übersetzungsfunktionen, auf Handschriften-, Text-im-Bild- oder Bildinhaltserkennung.
Umschreibedienste
Übersetzungsdienste
Bildgeneratoren
- https://openai.com/product/dall-e-2
- https://stablediffusionweb.com/
- https://www.midjourney.com/
- https://thispersondoesnotexist.com/ (momentan nicht erreichbar, 02.03.2023)
Stimmsynthese
Videosynthese
Der Artikel "Künstliche Intelligenz und Hochschule'" von Martin Smaxwil ist incl. aller Videos lizenziert unter einer CC-by-sa-4.0-Lizenz. Weitere Details dazu finden Sie unter https://moodle.thga.de/licensing.
Vielen Dank für die umfassende und trotzdem übersichtliche Zusammenstellung der Lage 🙂
Ich habe noch nicht alles gelesen, melde mich aber mit einem konkreteren Erfahrungsbericht zum Thema. Sehr spanned und danke für die übersichtliche und umfassende Zusammenstellung.
Danke. Wir können Ihren Erfahrungsbericht gern hier für die Allgemeinheit verlinken, falls gewünscht. Dafüer gerne melden 🙂
Danke für die Zusammenfassung! Insbesondere das versuchte Fazit.
Ich werde in meiner Programmierungsvorlesung auf jeden Fall versuchen ChatGPT als unterstützendes Werkzeug einzubringen!